Azure-native legal contract intelligence · proof of concept · source on GitHub ↗
Contract Intelligence
contract review & clause comparison
A pipeline that ingests legal contracts, extracts structured metadata with page-level citations, answers natural-language questions, and compares clauses against a versioned gold standard — built so a legal team can trust every answer. SQL decides the facts; retrieval supplies the evidence; the model only explains what it can cite.
- 2runtimes — Azure & local docker-compose, one codebase
- 0LLM tokens for canonical reporting queries
- ~70%domain-agnostic substrate, reusable elsewhere
- 100%of answers carry document + page citations
01 — Orchestration
A router that knows when not to spend
Most real questions over a contract corpus are old-school structured queries — “show me / list / how many”. Those should never cost an LLM call. The router resolves intent in layers, paying for language understanding only when the question actually needs it.
Tier 1 — deterministic
Rule-routed
A tiny regex shortcut catches canonical reporting phrasings and goes straight to SQL.
0 tokens · ~8 ms · $0
Tier 2 — SLM-first
LLM-routed → reporting
No rule match? A small classifier reads the intent — and can still land on the cheap SQL path for non-canonical phrasings like “show me expired”.
~600 router tokens → SQL
Tier 3 — full reasoning
Search & comparison
Genuine content questions route to RAG or a clause-vs-gold diff, where the token spend buys real work.
embeddings + reasoning LLM
The badge row under every answer makes the tier visible — routing, confidence, data sources, tokens, latency, cost.
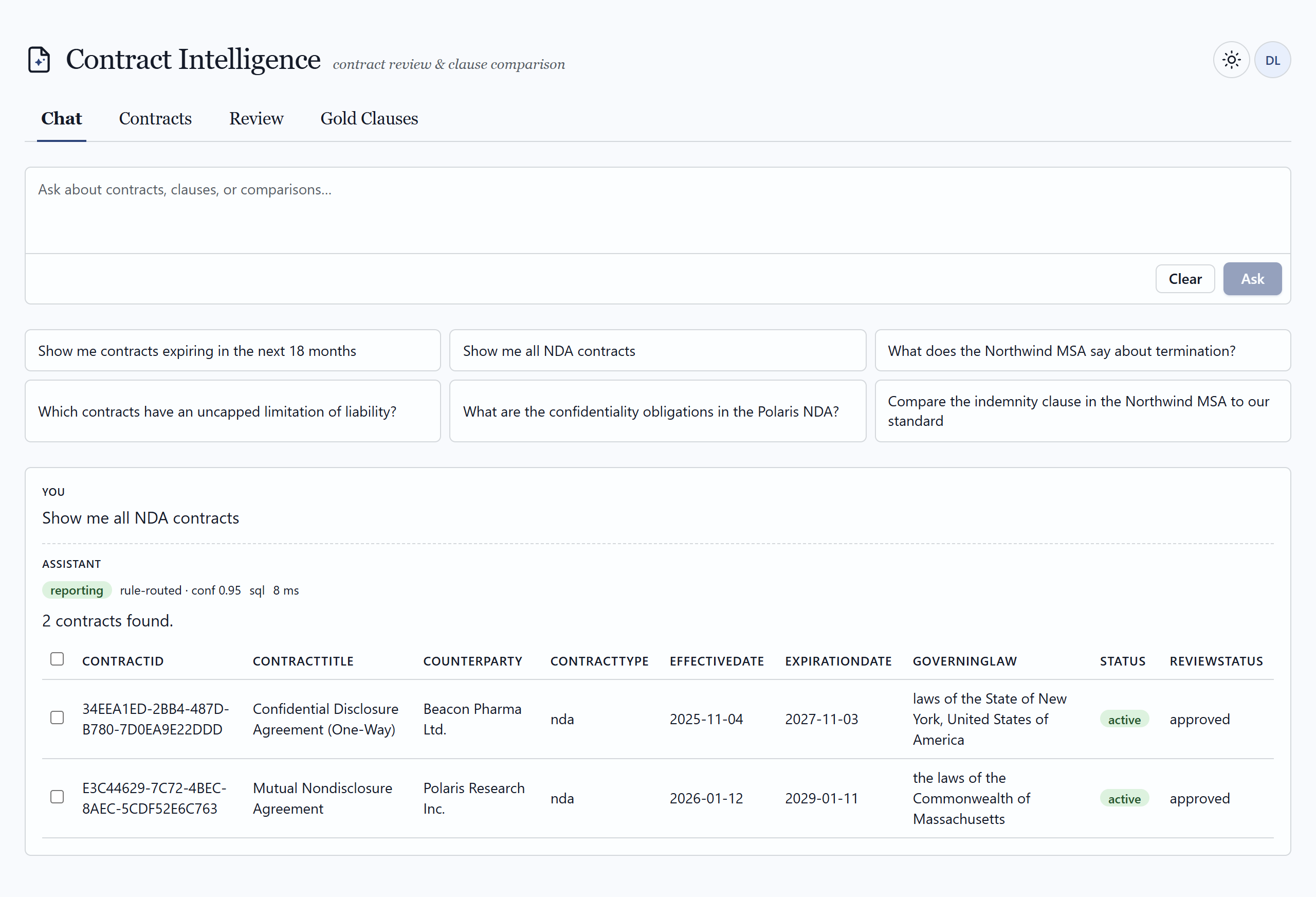
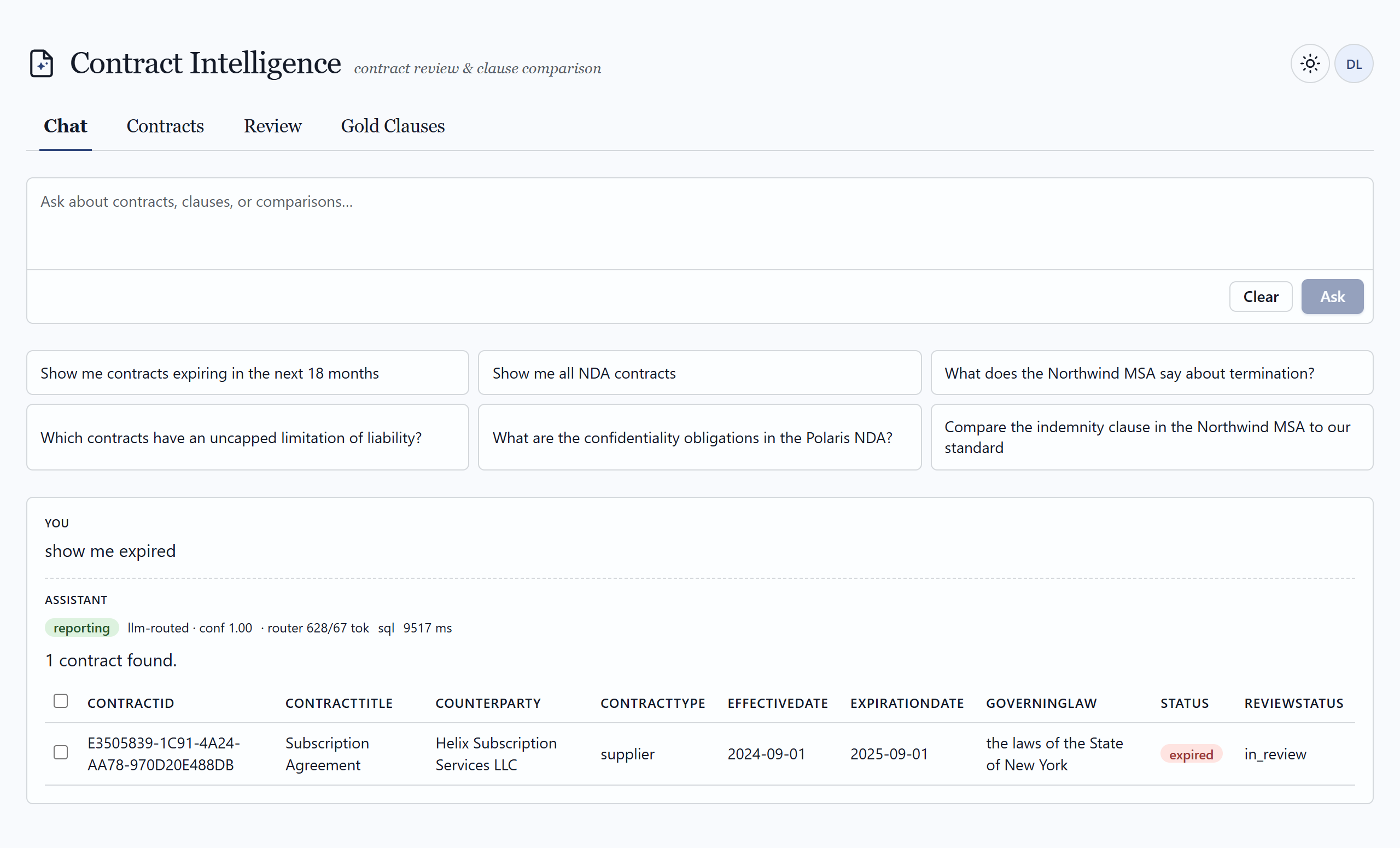
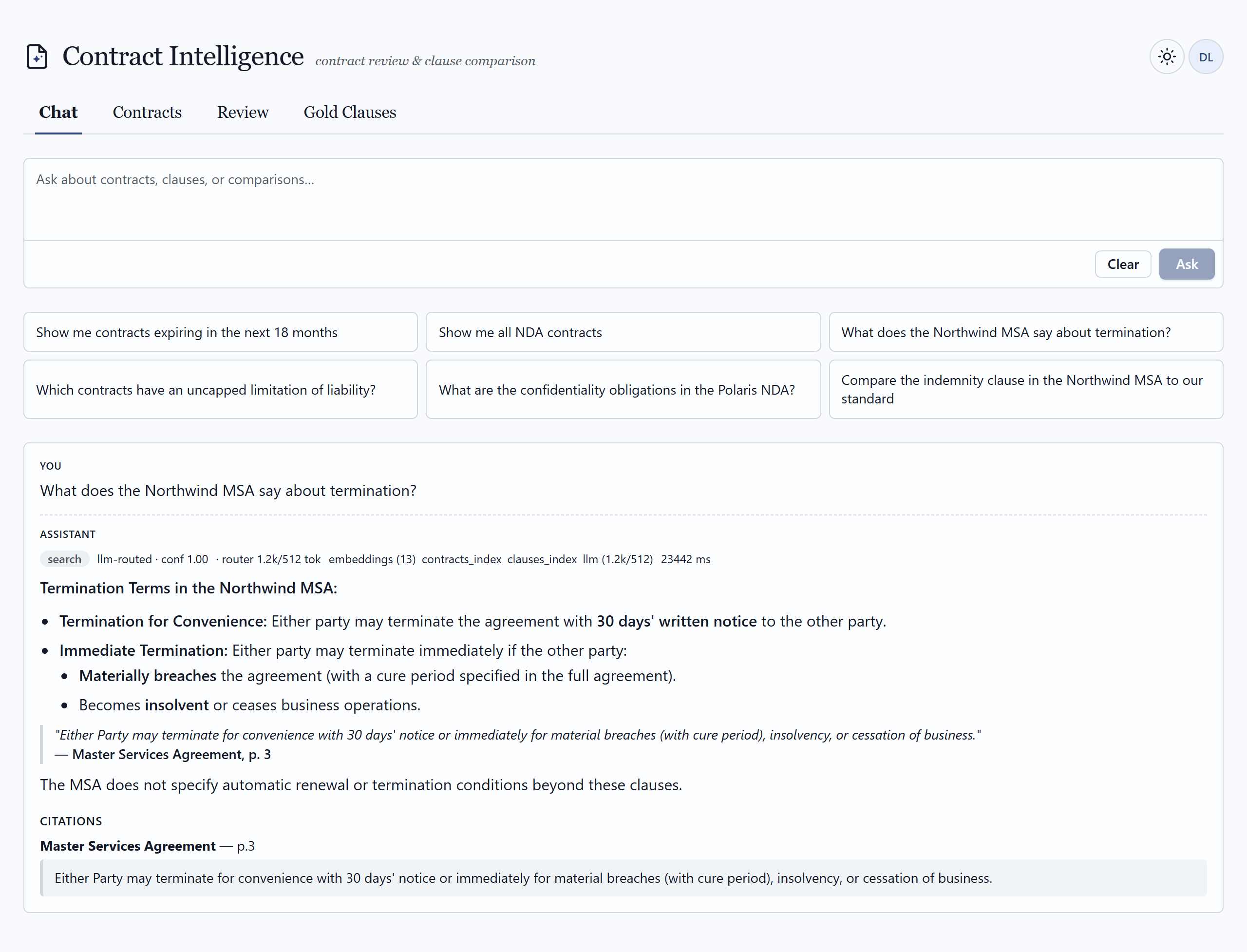
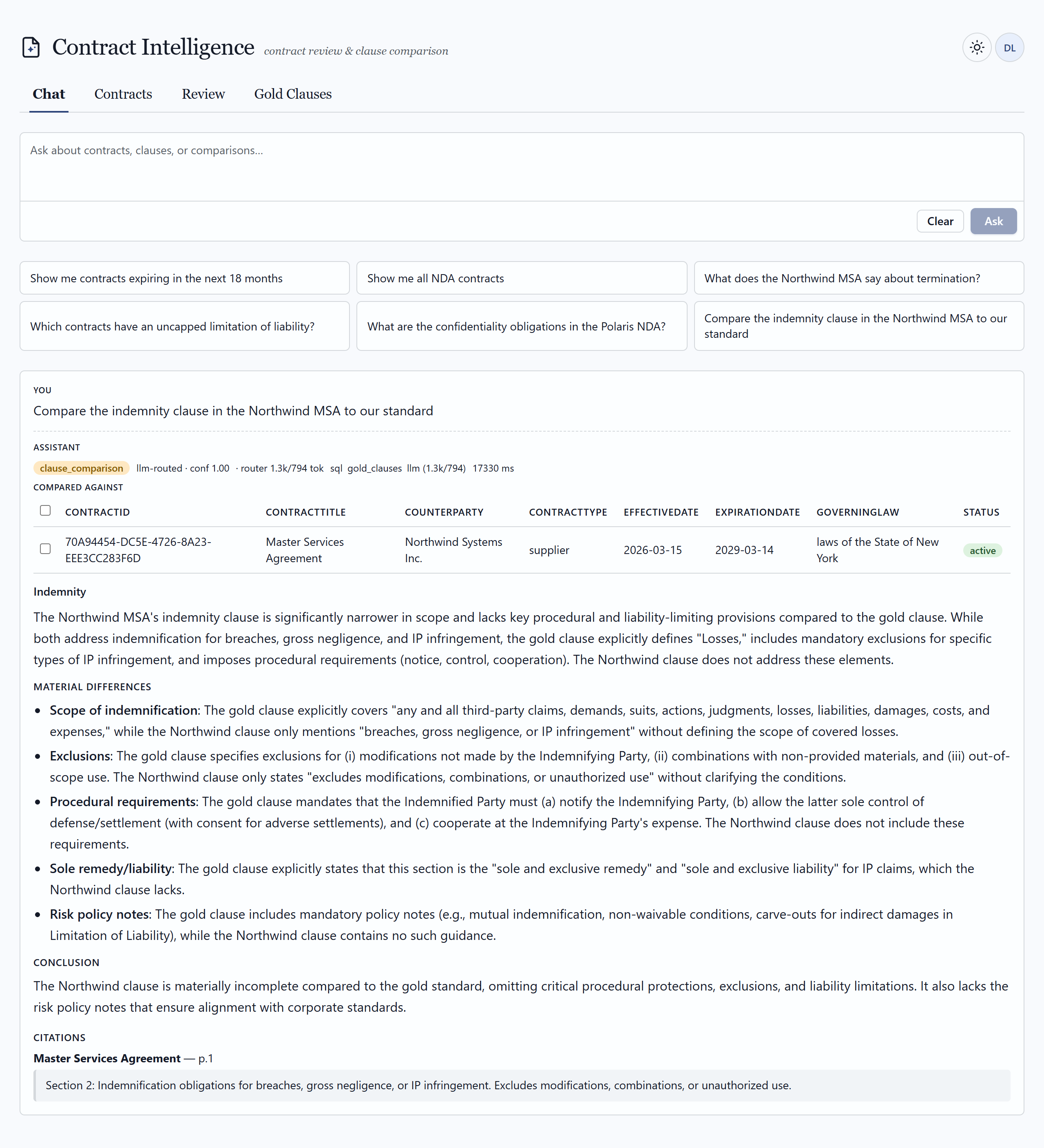
02 — The application
What a reviewer actually sees
A pro-code web surface — full control over routing, citations, comparison, and the human-in-the-loop workflow. Click any frame to view it full size.
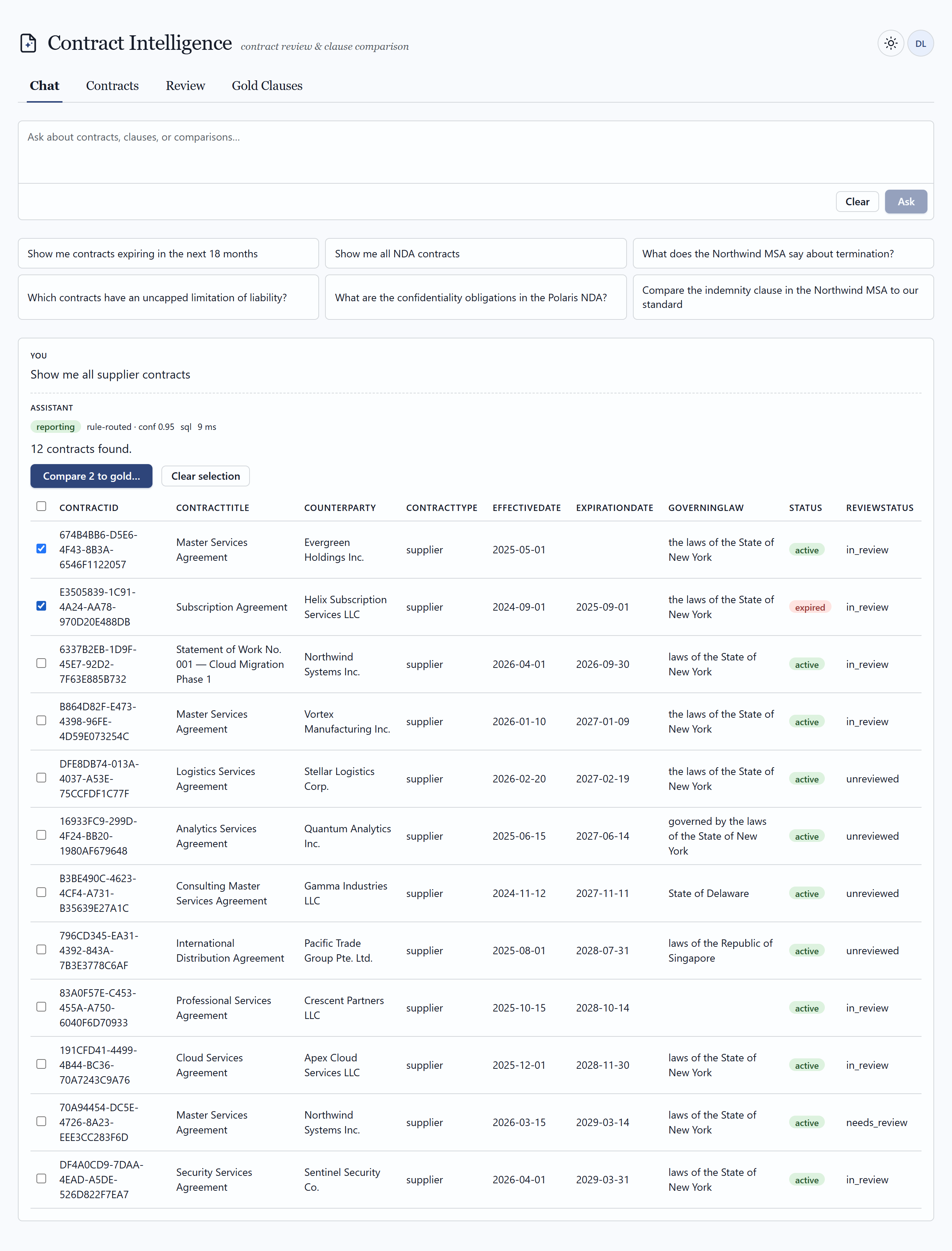
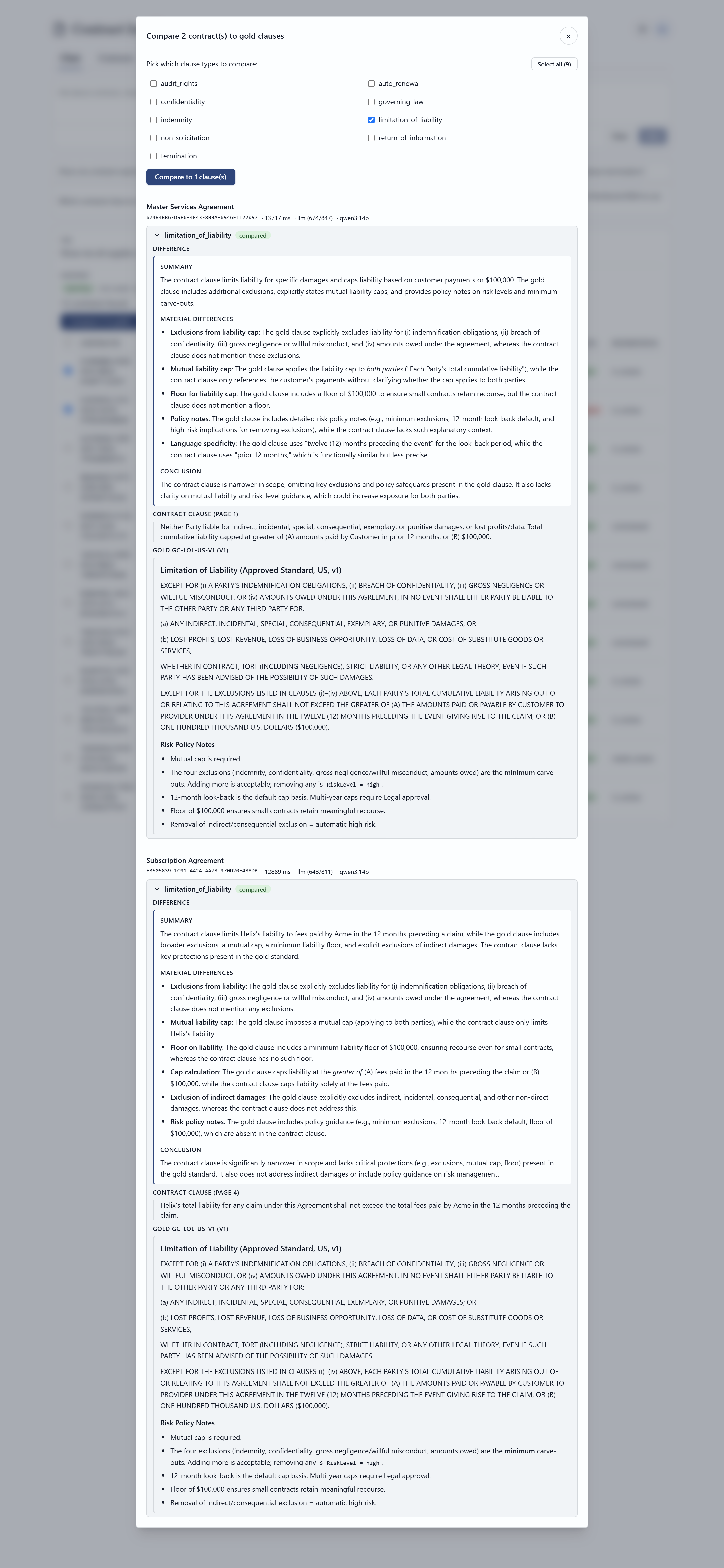
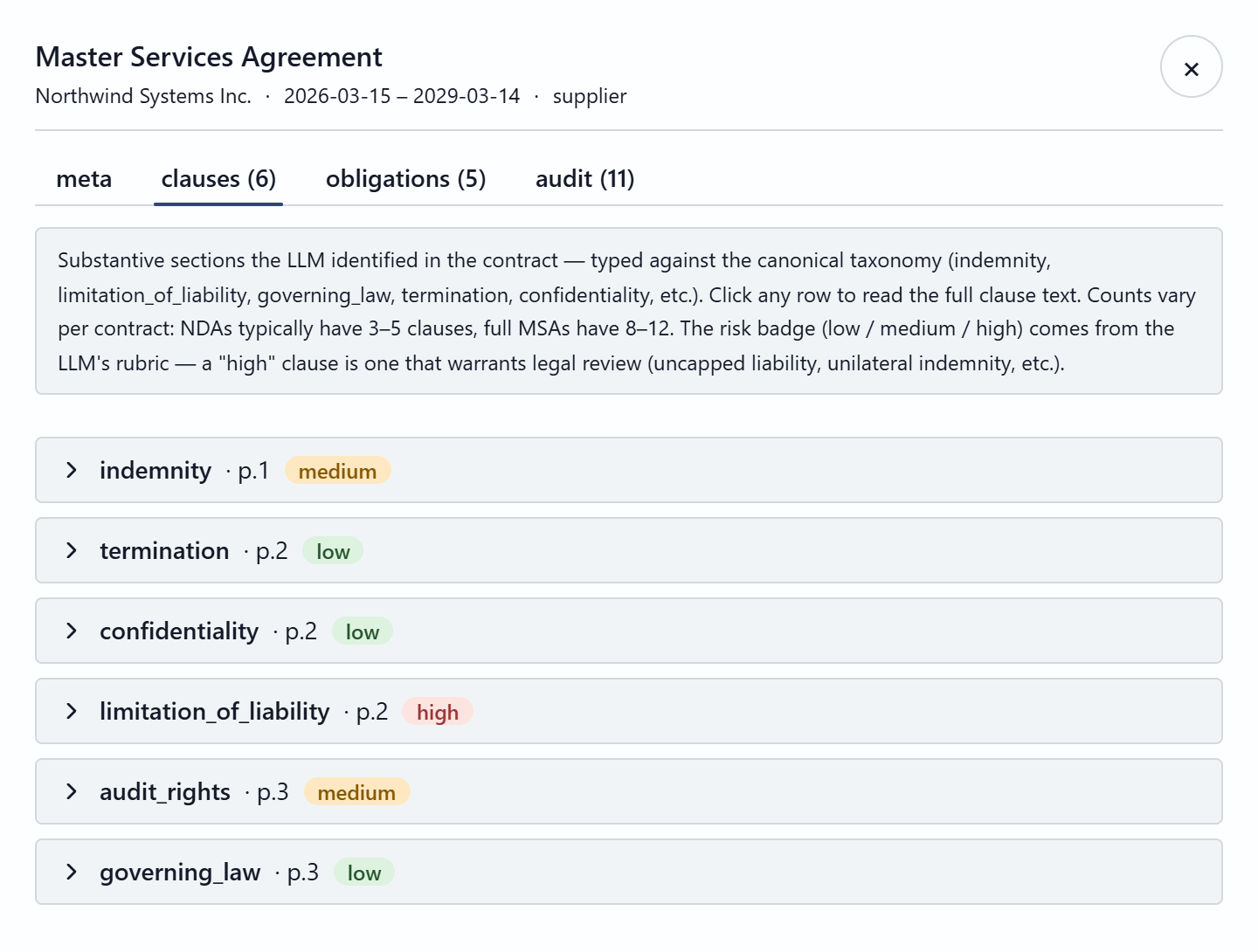
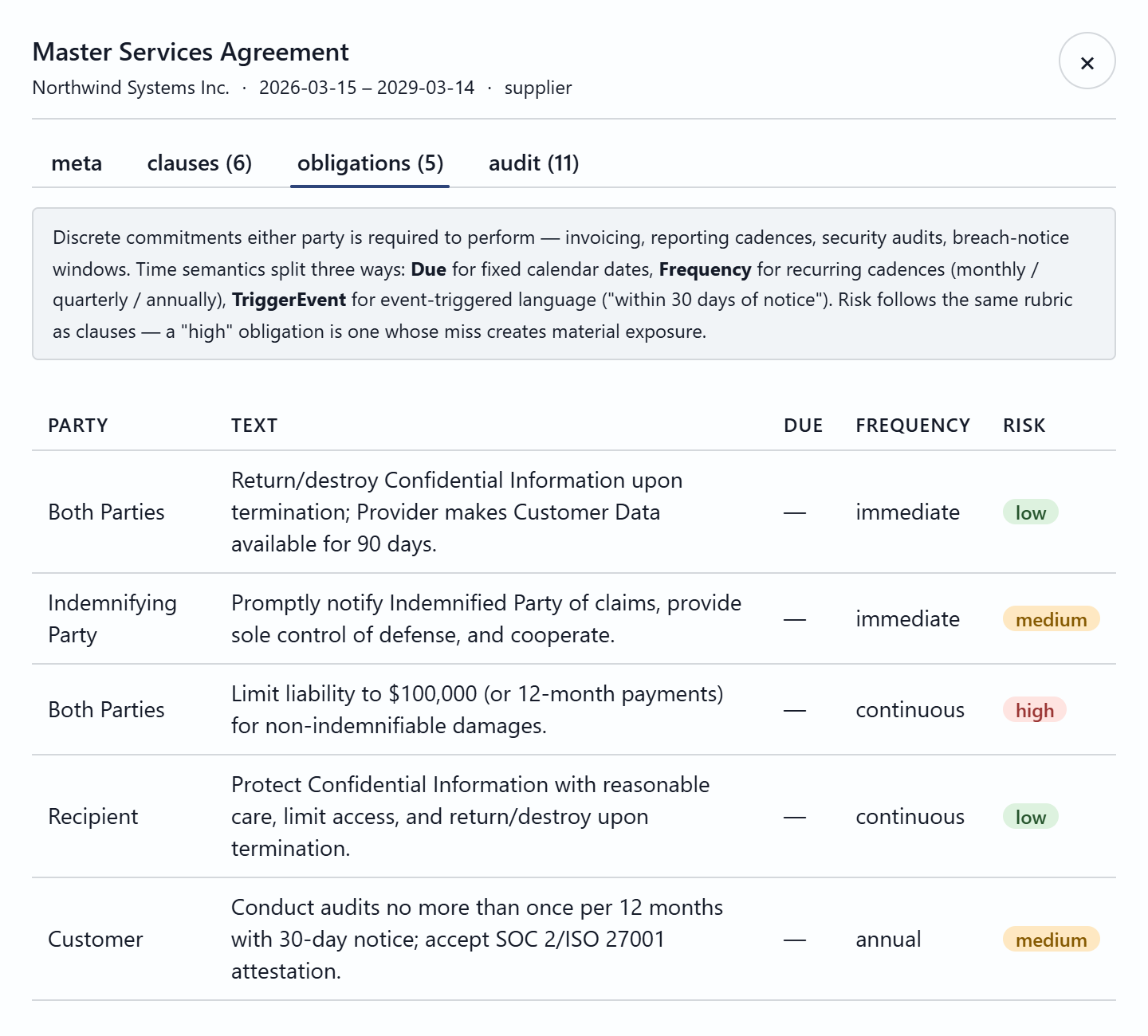
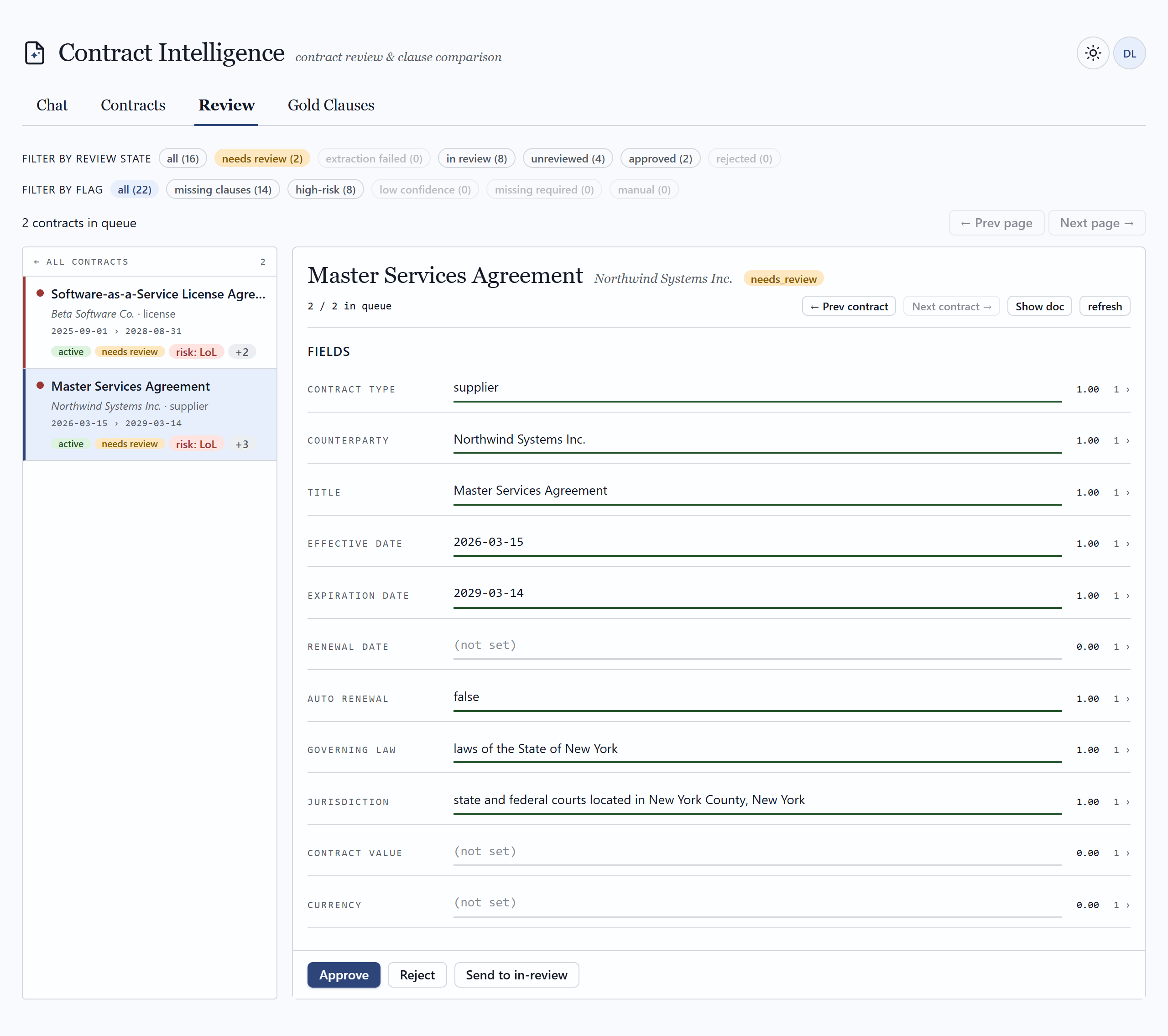
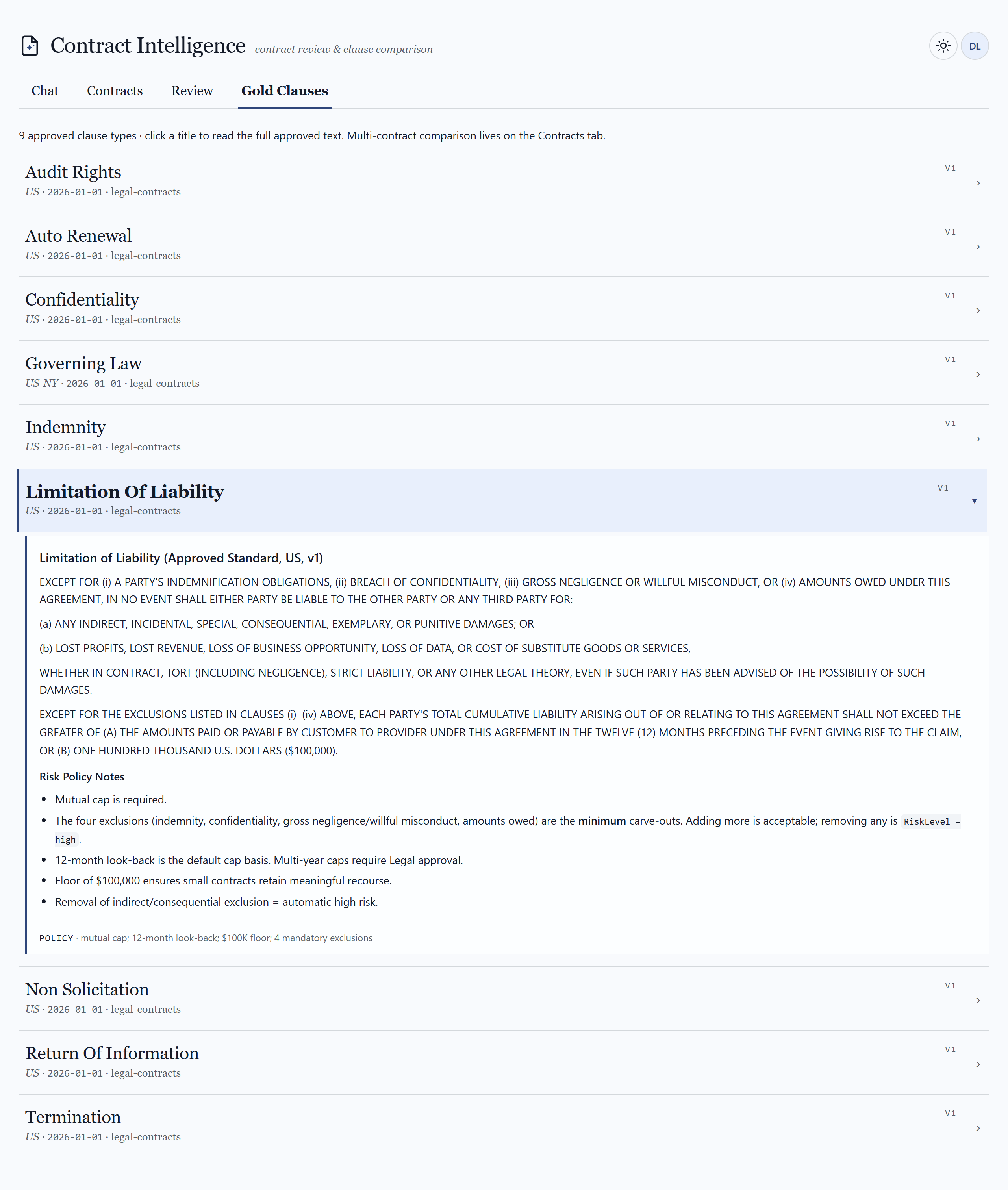

03 — Ingestion
Understand once, at write-time
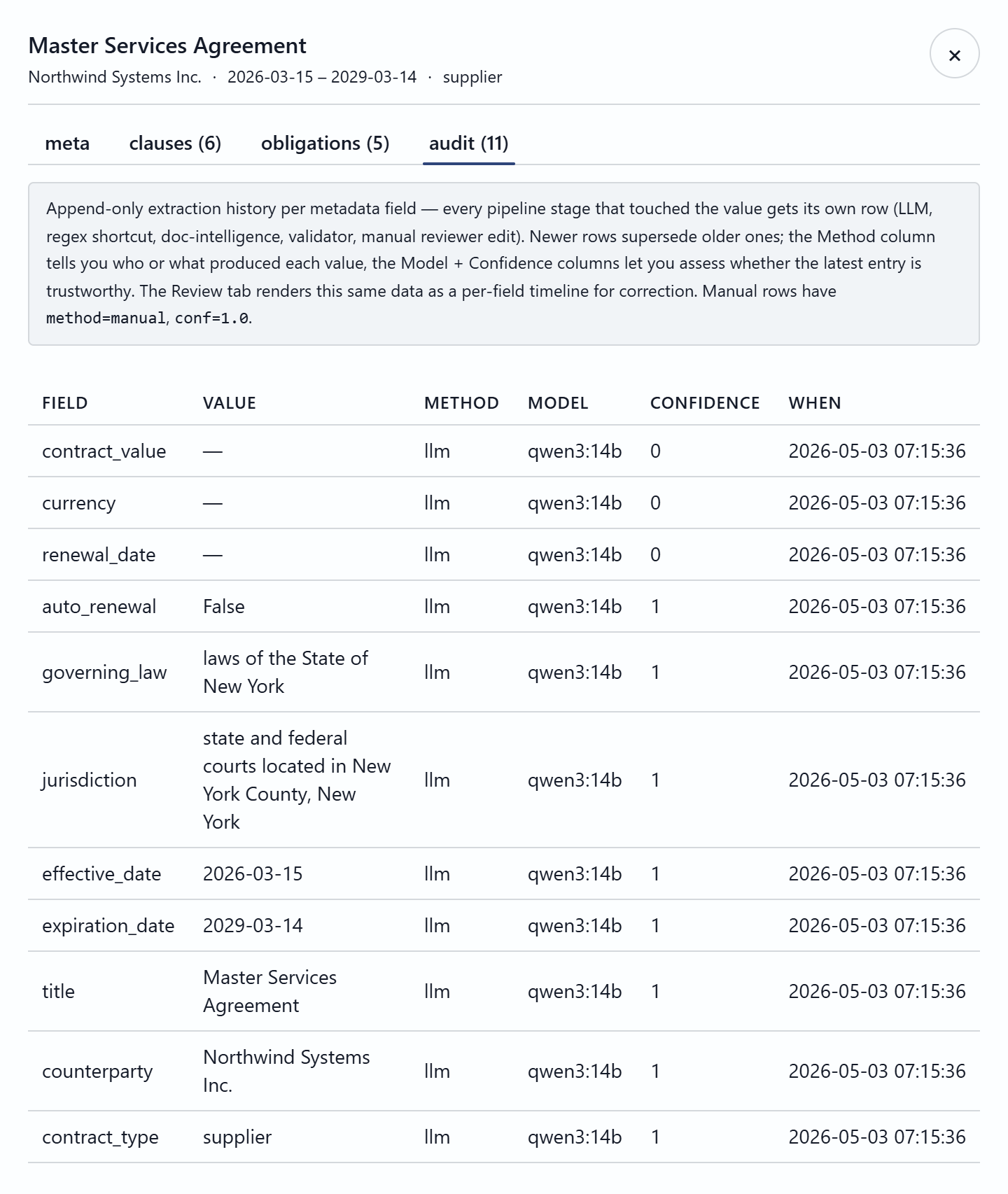
The expensive AI work — layout parsing, metadata / clause / obligation extraction with per-field confidence, and embeddings — runs once as a document lands, populating a structured metadata database. Query time then reads that pre-built structure cheaply, instead of re-deriving facts from raw documents on every request.

04 — Architecture
One codebase, two runtimes
Profile branching lives entirely in client factories, so the pipeline, router, and API never ask which environment they’re in. The production profile is Azure-native and managed-identity throughout; the local profile is a full docker-compose stack with zero cloud dependencies.
| Capability | Azure (production) | Local (docker-compose) |
|---|---|---|
| Documents | ADLS Gen2 / Blob | Azurite |
| Layout | Document Intelligence (prebuilt-layout) | unstructured.io |
| Extraction & reasoning | Azure OpenAI · gpt-4.1-mini / gpt-4.1 | Ollama · qwen3 |
| Embeddings | text-embedding-3-small (1536-d) | mxbai-embed-large (1024-d) |
| Source of truth | Azure SQL (serverless) | SQL Server 2022 |
| Retrieval | AI Search Basic — 2 indexes, semantic ranker | Qdrant — vector + filter |
| Ingestion trigger | Event Grid → Functions (push) | Polling watcher (~5 s) |
| Query API | Azure Functions | FastAPI |
05 — Evidence
A measurable playground
The local stack plus a synthetic corpus and an eval harness make this a sandbox for the full spread of questions a user actually asks — and a way to measure whether the answers hold up.
- 16synthetic contracts — clean baselines, single-clause deviations, missing-field cases
- 9approved gold clause types in the reference library
- 25golden Q&A across all five intent paths
- high‑90s%field-extraction accuracy on the local stack
The model is first-draft data; the reviewer is the source of truth. Every human correction is also a labeled example — the audit trail doubles as a growing evaluation set.
06 — Generalization
The same machine, other domains
Strip away the legal vocabulary and what remains is a generic shape: ingest documents → extract structured fields and chunks → embed and index → answer via a router over RAG and structured lookup → compare snippets against a curated reference set. Roughly two-thirds of the code never knew it was about contracts.
Reused as-is
- Profile-aware client factories — same Azure / local seam
- Ingestion pipeline shape — idempotent hash-based upsert
- Router + handler dispatch and the SQL builder
- Vector-search abstraction — two indexes, filtered purge
- Structured-output prompting, coercions, OpenAPI
- Eval harness, both infra stacks, the audit pattern
Swapped per domain
- Entity schema — the tables and what’s extracted
- Extraction prompt & JSON schema
- Router rules & intents, the filter parser
- Reporting SQL projection and labels
- Comparison-to-gold reference set
- Synthetic corpus + manifest for the new domain
~75% reuse
Sales call notes
Action items, sentiment, next steps — measured against stage playbooks instead of gold clauses.
~70% reuse
Survey free-text
Themes, sentiment, risk flags against a canonical theme taxonomy; adds a trend / aggregation intent.
~65% reuse
Support transcripts
Resolution and escalation risk against an agent-behaviour rubric; the clauses index becomes a turns index.
Estimated effort to repurpose the substrate for a new domain: roughly two to three person-weeks.